JDK 中基于数组的阻塞队列 ArrayBlockingQueue 原理剖析,ArrayBlockingQueue 内部如何基于一把独占锁以及对应的两个条件变量实现出入队操作的线程安全?
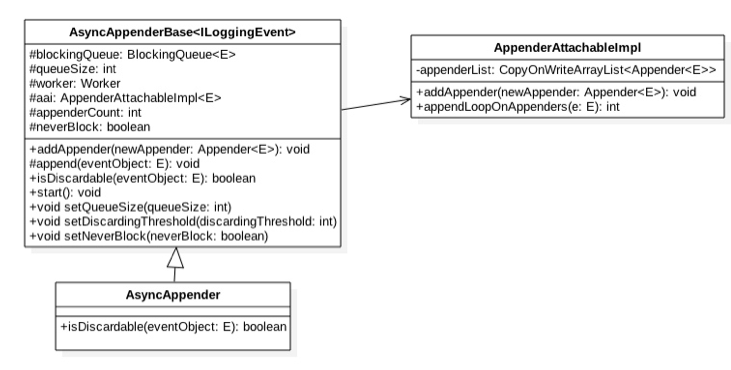
首先我们先大概的浏览一下ArrayBlockingQueue 的内部构造,如下类图:
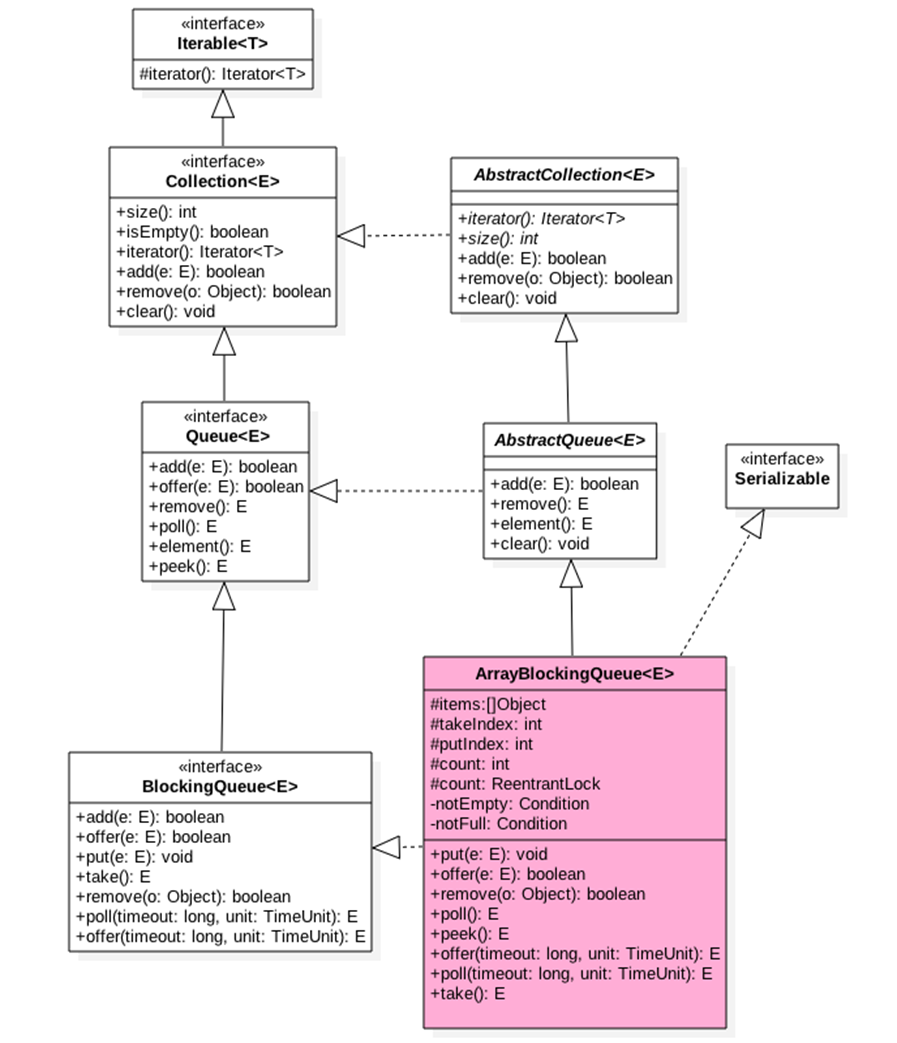
如类图所示,可以看到ArrayBlockingQueue 内部有个数组items 用来存放队列元素,putIndex变量标示入队元素的下标,takeIndex是出队的下标,count是用来统计队列元素个数,
从定义可以知道,这些属性并没有使用valatile修饰,这是因为访问这些变量的使用都是在锁块内被用。而加锁了,就足以保证了锁块内变量的内存可见性。
另外还有个独占锁lock 用来保证出队入队操作的原子性,这保证了同时只有一个线程可以进行入队出队操作,另外notEmpty,notFull条件变量用来进行出队入队的同步。
由于ArrayBlockingQueue 是有界队列,所以构造函数必须传入队列大小的参数。
接下来我们进入ArrayBlockingQueue的源码看,如下:
public ArrayBlockingQueue(int capacity) { this(capacity, false);} public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } 如上面代码所示,默认情况下使用的是ReentrantLock提供的非公平独占锁进行入队出队操作的加锁。
接下来主要看看ArrayBlockingQueue的主要的几个操作的源码,如下:
1.offer 操作,向队列尾部插入一个元素,如果队列有空闲容量,则插入成功后返回true,如果队列已满则丢弃当前元素,然后返回false,
如果e元素为null,则抛出 NullPointerException 异常,另外该方法是不阻塞的。源码如下:
public boolean offer(E e) { //(1)e为null,则抛出NullPointerException异常 checkNotNull(e); //(2)获取独占锁 final ReentrantLock lock = this.lock; lock.lock(); try { //(3)如果队列满则返回false if (count == items.length) return false; else { //(4)否者插入元素 enqueue(e); return true; } } finally { lock.unlock(); } } 代码(2)获取独占锁,当前线程获取到该锁后,其他入队和出队操作的线程都会被阻塞挂起后放入lock锁的AQS阻塞队列。
代码(3)如果队列满则直接返回false,否则调用enqueue方法后返回true,enqueue的源码如下:
private void enqueue(E x) { //(6)元素入队 final Object[] items = this.items; items[putIndex] = x; //(7)计算下一个元素应该存放的下标 if (++putIndex == items.length) putIndex = 0; count++; //(8) notEmpty.signal(); } 可以看到上面代码首先把当前元素放入items数组,然后计算下一个元素应该存放的下标,然后递增元素个数计数器,最后激活 notEmpty 的条件队列中因为调用 poll 或者 take 操作而被阻塞的的一个线程。
这里由于在操作共享变量,比如count前加了锁,所以不存在内存不可见问题,加过锁后获取的共享变量都是从主存获取的,而不是在CPU缓存获取寄存器里面的值。
代码(5)释放锁,释放锁后会把修改的共享变量值,比如Count的值刷新回主内存中,这样其他线程通过加锁再次读取这些共享变量后就可以看到最新的值。
2.put操作,向队列尾部插入一个元素,如果队列有空闲则插入后直接返回true,如果队列已满则阻塞当前线程直到队列有空闲插入成功后返回true,
如果在阻塞的时候被其他线程设置了中断标志,则被阻塞线程会抛出InterruptedException 异常而返回,另外如果 e 元素为 null 则抛出 NullPointerException 异常。源码如下:
public void put(E e) throws InterruptedException { //(1) checkNotNull(e); final ReentrantLock lock = this.lock; //(2)获取锁(可被中断) lock.lockInterruptibly(); try { //(3)如果队列满,则把当前线程放入notFull管理的条件队列 while (count == items.length) notFull.await(); //(4)插入元素 enqueue(e); } finally { //(5) lock.unlock(); }} 代码(2)在获取锁的过程中当前线程被其它线程中断了,则当前线程会抛出 InterruptedException 异常而退出。
代码(3)判断如果当前队列满了,则把当前线程阻塞挂起后放入到 notFull 的条件队列,注意这里是使用了 while 而不是 if。为什么需要while呢?
这是因为考虑到当前线程被虚假唤醒的问题,也就是其它线程没有调用 notFull 的 singal 方法时候,notFull.await() 在某种情况下会自动返回。
如果使用if语句简单判断一下,那么虚假唤醒后会执行代码(4),元素入队,并且递增计数器,而这时候队列已经是满了的,导致队列元素个数大于了队列设置的容量,导致程序出错。
而使用使用 while 循环假如 notFull.await() 被虚假唤醒了,那么循环在检查一下当前队列是否是满的,如果是则再次进行等待。
代码(4)如果队列不满则插入当前元素。
3.poll操作,从队列头部获取并移除一个元素,如果队列为空则返回 null,该方法是不阻塞的。源码如下:
public E poll() { //(1)获取锁 final ReentrantLock lock = this.lock; lock.lock(); try { //(2)当前队列为空则返回null,否者调用dequeue()获取 return (count == 0) ? null : dequeue(); } finally { //(3)释放锁 lock.unlock(); }} 代码(1)获取独占锁
代码(2)如果队列为空则返回 null,否者调用 dequeue() 方法,dequeue 源码如下:
private E dequeue() { final Object[] items = this.items; //(4)获取元素值 @SuppressWarnings("unchecked") E x = (E) items[takeIndex]; //(5)数组中值值为null; items[takeIndex] = null; //(6)队头指针计算,队列元素个数减一 if (++takeIndex == items.length) takeIndex = 0; count--; //(7)发送信号激活notFull条件队列里面的一个线程 notFull.signal(); return x;} 如上代码,可以看到首先获取当前队头元素保存到局部变量,然后重置队头元素为null,并重新设置队头下标,元素计数器递减,最后发送信号激活notFull 的条件队列里面一个因为调用 put 或者 offer 而被阻塞的线程。
4.take 操作,获取当前队列头部元素,并从队列里面移除,如果队列为空则阻塞调用线程。如果队列为空则阻塞当前线程知道队列不为空,然后返回元素,
如果如果在阻塞的时候被其它线程设置了中断标志,则被阻塞线程会抛出 InterruptedException 异常而返回。源码如下:
public E take() throws InterruptedException { //(1)获取锁 final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { //(2)队列为空,则等待,直到队列有元素 while (count == 0) notEmpty.await(); //(3)获取队头元素 return dequeue(); } finally { //(4) 释放锁 lock.unlock(); }} 可以看到take操作的代码也比较简单,与poll相比,只是步骤(2)如果队列为空,则把当前线程挂起后放入到notEmpty的条件队列,等其他线程调用notEmpty.signal() 方法后在返回,
需要注意的是这里也是使用 while 循环进行检测并等待而不是使用 if。之所以这样做,道理都是一样。这里就不在解释了。
5.peek 操作获取队列头部元素但是不从队列里面移除,如果队列为空则返回 null,该方法是不阻塞的。源码如下:
public E peek() { //(1)获取锁 final ReentrantLock lock = this.lock; lock.lock(); try { //(2) return itemAt(takeIndex); } finally { //(3) lock.unlock(); }} @SuppressWarnings("unchecked")final E itemAt(int i) { return (E) items[i];} peek的实现更加简单,首先获取独占锁,然后从数组items 中获取当前队头下标的值并返回,在返回之前释放了获取的锁。
6. size 操作,获取当前队列元素个数。源码如下:
public int size() { final ReentrantLock lock = this.lock; lock.lock(); try { return count; } finally { lock.unlock(); }} size 操作是简单的,获取锁后直接返回 count,并在返回前释放锁。也许你会有疑问这里有没有修改Count的值,只是简单的获取下,为何要加锁呢?
答案很简单,如果count声明为volatile,这里就不需要加锁了,因为因为 volatile 类型变量保证了内存的可见性,而 ArrayBlockingQueue 的设计中 count 并没有声明为 volatile,
这是因为count的操作都是在获取锁后进行的,而获取锁的语义之一就是获取锁后访问的变量都是从主内存获取的,这就保证了变量的内存可见性。
最后用一张图来加深对ArrayBlockingQueue的理解,如下图:
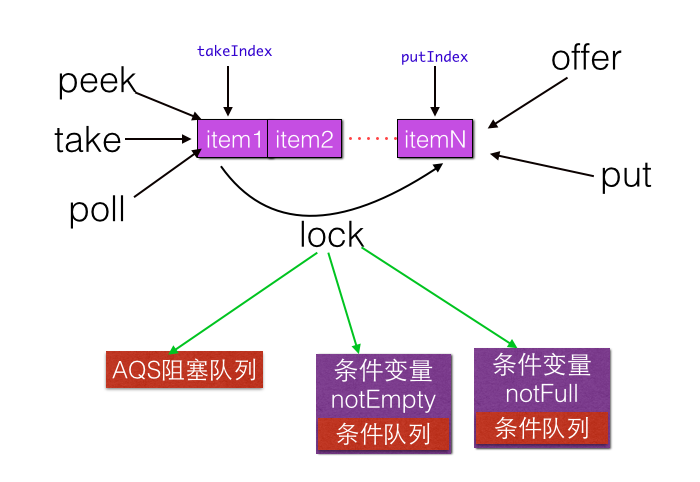
总结:ArrayBlockingQueue 通过使用全局独占锁实现同时只能有一个线程进行入队或者出队操作,这个锁的粒度比较大,有点类似在方法上添加 synchronized 的意味。ArrayBlockingQueue 的 size 操作的结果是精确的,因为计算前加了全局锁。
二、Logback 框架中异步日志打印中 ArrayBlockingQueue 的使用
在高并发并且响应时间要求比较小的系统中同步打日志已经满足不了需求了,这是因为打日志本身是需要同步写磁盘的,会造成 响应时间 增加,如下图同步日志打印模型为:
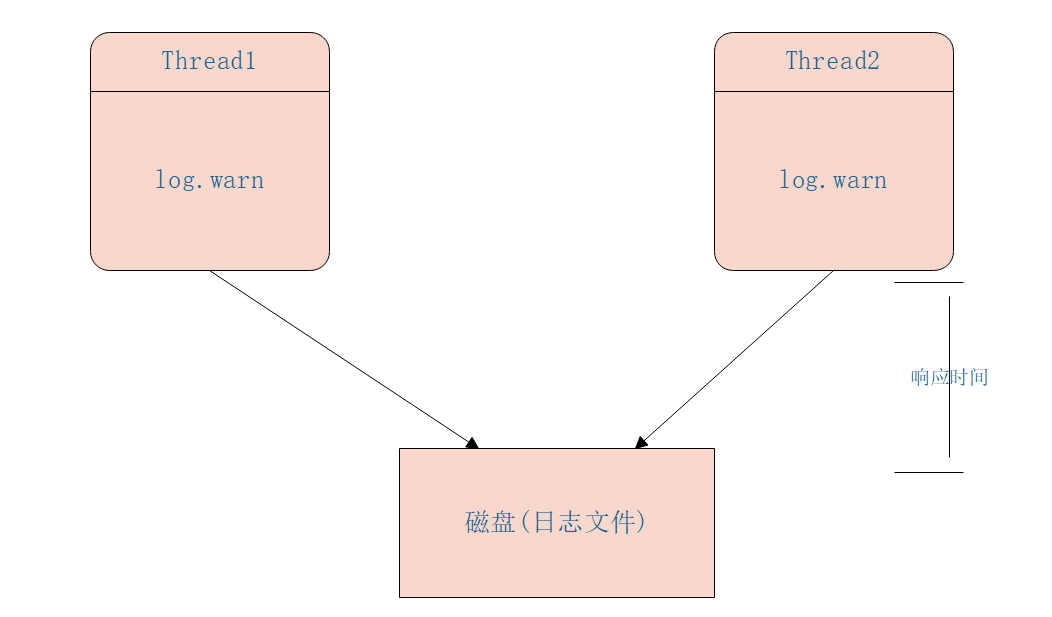
异步模型是业务线程把要打印的日志任务写入一个队列后直接返回,然后使用一个线程专门负责从队列中获取日志任务写入磁盘,其模型具体如下图:
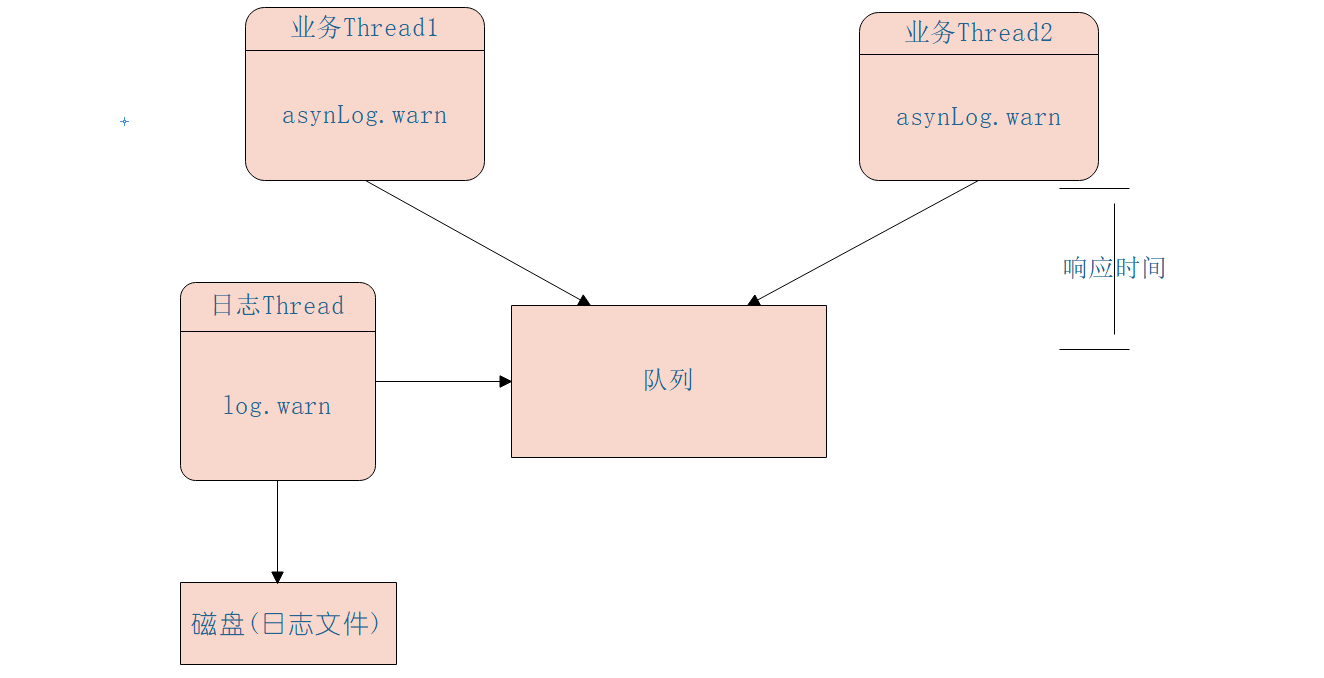
如图可知其实 logback 的异步日志模型是一个多生产者单消费者模型,通过使用队列把同步日志打印转换为了异步,业务线程调用异步 appender 只需要把日志任务放入日志队列,日志线程则负责使用同步的 appender 进行具体的日志打印到磁盘。
接下来看看异步日志打印具体实现,要把同步日志打印改为异步需要修改 logback 的 xml 配置文件如下:
project.log UTF-8 true project.log.%d{yyyy-MM-dd} 7